Every developer does it subconsciously nowadays. We create a database schema and we normalize it without thinking about it. At least I hope we do. We let the data speak for itself. Sometimes that doesn't turn out so well, and sometimes it isn't terrible.
There are several goals when designing a database that I try to keep in mind. A few include reducing the amount of duplicate data, making the data clear and readable and reducing the number of changes needed to the code whenever new data sets are introduced. It's always nice coming back to an old project and having it make sense without having to relearn how it works.
Database Normalization is the process of organizing the fields and tables in a relational database in order to reduce any unnecessary redundancy. The process usually involves breaking down larger tables (many columns) into smaller more manageable tables and relating the two using primary keys and foreign keys. It usually follows common logic, for example a User table can have an Address associated with it, and while that data can be added to the User table it might be better off doing it's own thing in the Address table. Addresses can further have the type of the address since users can have multiple addresses or state information. Normalization reduces complexity overall and can improve querying speed. Too much normalization, however, can be just as bad as it comes with its own set of problems. I've worked at several companies and I've seen both first hand and it's a pain when it's done wrong and its an early day when it's done correctly.
Can we avoid database normalization?
If you don't worry about normalization, then you're in for an easy ride in your development career, at least at first. You just add any fields that you may need to your main table. Using the User table example, we can have a table such as the following:
Easy to implement, not much work went into it and it shrinks your queries down as everything you need is in this one table.
SELECT * FROM User
Tons of problems with this schema, however, that you won't see until you spend some time with the data. Some people believe that you should worry about design when you have large amounts of traffic, but believe me, as soon as you start to get 10,000 or 100,000 daily rows into a table, you won't be making design changes.
don't wait until the problems present themselves
I once worked on an internal system that had database tables each with several hundred columns. The reason it had several hundred was that data was repeated several times throughout its schema due to the fact that the developers kept forgetting that the table already had certain columns, and so they were added again..and again..and again. Every new request that came in was met with new columns being added to the same table. About 90% of the table was 'null' values and after a certain amount of columns, it began to fail sporadically. Did it save time? Only during the initial first phase of development, while specs were getting worked out. After the system was live, it was almost impossible to query and went down all the time. Those hundreds of columns should have ended being several dozen database tables each with relation to each other.
More importantly, it's good to remember that real life people will be working on these systems. As someone who is a real-life person, there is nothing more daunting than taking over a database with tables that contain hundreds of unknown and cryptic columns. Normalized databases should by their nature make more logical sense to anyone laying their eyes on it for the first time. Sometimes, under time constraints developers get lazy and save time by cutting a few corners. Spending just a tiny bit of time in DB design leads to faster development in the future.
Too Much Normalization
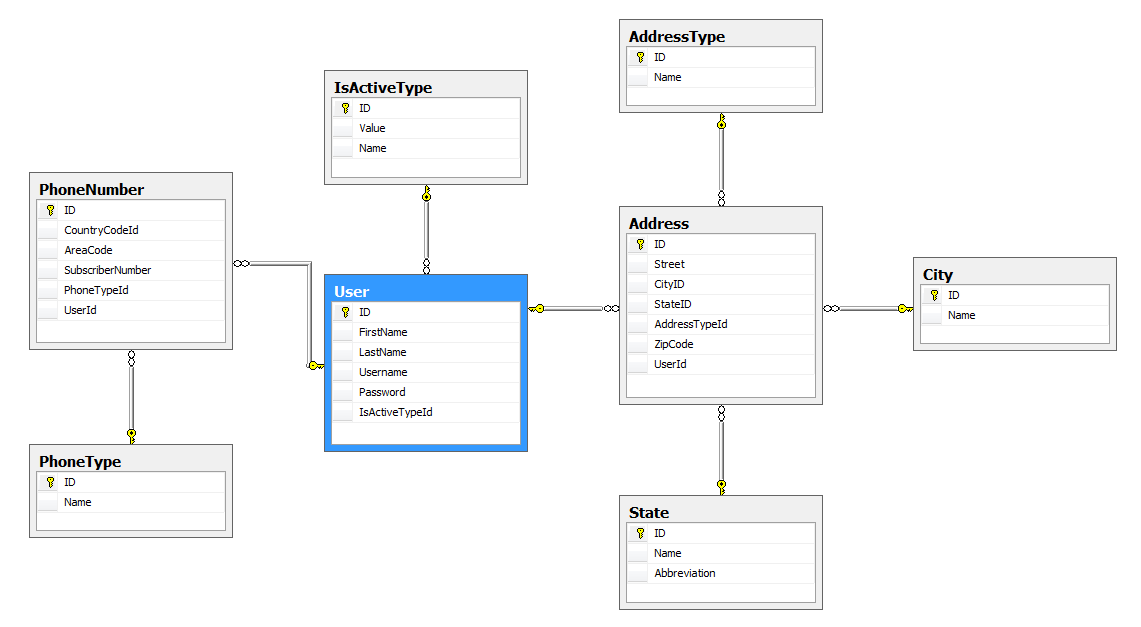
This is a problem that I mainly notice with technical managers who think they are developers. If you don't normalize you're in for some headaches down the road. But you can also normalize too much, to the point where a simple concept can end up having 100 arms spread out all over your database. It's more work and has very little benefit, aside from longer queries, some performance issues and bragging about your super normalized database. I once knew a man who believed that any boolean value in a database should be its own table just in case it one day stopped being a boolean value. Just in case "Active" for example stopped having "True" or "False" and ended up with a "Maybe" in between. The result, as you may imagine, was one of the worst things I ever worked on and had nothing to do with normalization. Every flag column became a foreign key pointing to another record with either a 'true' or a 'false'. An expensive conversion on an already stable system which caused months of headaches.
The example I had above isn't too 'normalized' by any means, however, it might be too normalized for your particular needs. For example, I probably didn't need a separate table for City as I probably won't be adding too much information about any particular city in general. IsActiveType is a needless addition to the design. You should normalize for your needs whenever you can. Any more and you're just piling on the joins in order to retrieve a simple string.
Just The Right Amount Of Normalization
If done correctly, a fully normalized database is easy to work with and it offers tons of benefits. A well formed design will need almost no modifications to existing code whenever new data sets are introduced. They run faster and queries make logical sense more importantly. The main thing to remember is to break down your data into their own logical units. An online storefront will have products which can further contain specifications which are sold through transactions. And those can be broken down further even.
With practice, your sweet spot in normalization comes naturally. You begin to design the system based on real-world objects. Based on the specifications and requirements you can mold the database to best fit your needs. If you're going to be working on a database day in and day out for a long while, you're going to want to be comfortable with working with the data. If you're loading a users profile, the last thing you're probably going to want to do is to write join query with 20 tables. Always normalize for your needs and for your system.
Walt is a computer scientist, software engineer, startup founder and previous mentor for a coding bootcamp. He has been creating software for the past 20 years.
Last updated on: